Abstract
We present RodinHD, which can generate high-fidelity 3D avatars from a portrait image. Existing methods fail to capture intricate details such as hairstyles which we tackle in this paper. We first identify an overlooked problem of catastrophic forgetting that arises when fitting triplanes sequentially on many avatars, caused by the MLP decoder sharing scheme. To overcome this issue, we raise a novel data scheduling strategy and a weight consolidation regularization term, which improves the decoder's capability of rendering sharper details. Additionally, we optimize the guiding effect of the portrait image by computing a finer-grained hierarchical representation that captures rich 2D texture cues, and injecting them to the 3D diffusion model at multiple layers via cross-attention. When trained on 46K avatars with a noise schedule optimized for triplanes, the resulting model can generate 3D avatars with notably better details than previous methods and can generalize to in-the-wild portrait input.
Conditional Avatar Generation from Synthetic Portrait
Avatar Creation from In-the-wild Portrait
Text-conditioned Avatar Creation
Unconditional Avatar Generation
Visual Comparison of 3D Consistency with Rodin
Note: The 3D digital avatars generated by our model are for research purposes only.
Method
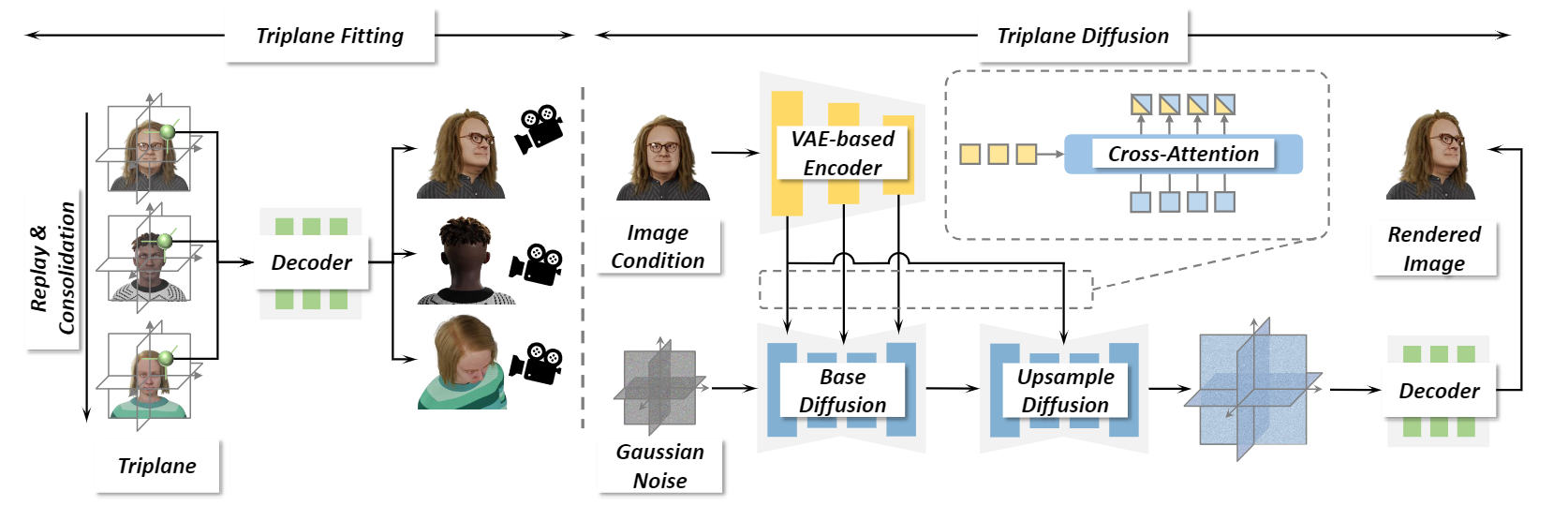
Our framework comprises two stages of triplane fitting and generation, respectively. In the fitting stage, it learns a high-resolution triplane for each avatar and a shared decoder for rendering images. In the generation stage, it learns a base diffusion model and an upsample diffusion model cascaded to generate high-resolution triplanes. The conditional portrait images are injected into the diffusion models in a hierarchical style to enhance the intricate details in the generated triplanes.
Catastrophic Forgetting

As training proceeds, the decoder gradually forgets the knowledge learned on the previous avatars of 1&4 and is overly adapted to avatar 9. As a result, the decoder lacks ability to generate fine details for novel triplanes. Therefore, we propose a novel data scheduling strategy called task replay, and a weight consolidation regularization term that effectively preserves the decoder's capability of rendering sharp details.
High-resolution Triplane Diffusion

Destruction comparison. Rendered images from triplanes with 8 and 32 channels, respectively. The triplanes are destructed with the same noise level (logSNR(t) = 0.57). The 32-channel triplane has larger redundancy so it is less destructed even with the same noise level. Considering the larger redundancy in triplanes, we propose to apply a stronger noise to fully destruct triplanes to prevent the model from under-training.
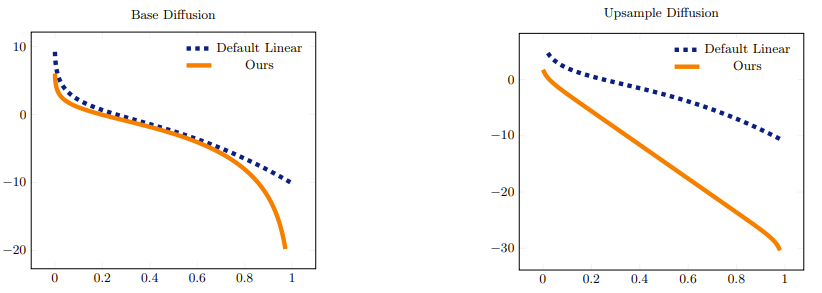
Visualization of optimized noise schedule. LogSNR comparison between the default setting and our optimized noise schedules for the base (left) and upsample (right) networks.
Despite this, it is difficult to hallucinate detailed 3D avatars from scratch. So, we propose to supply ample details from the portrait image to alleviate the difficulty. We compute a multi-scale feature representation using a pre-trained Variational Autoencoder. Since the VAE is trained to accurately reconstruct the input images, the low-level visual details are well preserved in the latent features.
Demo Video
BibTeX
@article{zhang2024rodinhd,
title={RodinHD: High-Fidelity 3D Avatar Generation with Diffusion Models},
author={Zhang, Bowen and Cheng, Yiji and Wang, Chunyu and Zhang, Ting and Yang, Jiaolong and Tang, Yansong and Zhao, Feng and Chen, Dong and Guo, Baining},
journal={arXiv preprint arXiv:2407.06938},
year={2024}
}